
Oracle到OceanBase数据迁移OMS最佳实践
作者:OceanBase数据库学堂 更新时间:2025-06-11 17:36:42 共932人关注

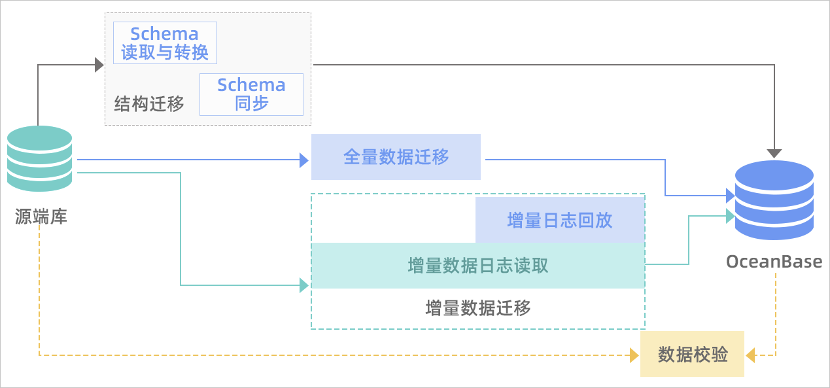
OceanBase 迁移服务(OceanBase Migration Service,OMS)是 OceanBase 提供的一种支持同构或异构RDBMS与 OceanBase 之间进行数据交互的服务,具备在线迁移存量数据和实时同步增量数据的能力。
本文以国内某保险客户核心系统FF分布式升级为例,介绍Oracle到 OceanBase 数据迁移最佳实践。
 FF系统Oracle到 OceanBase 数据迁移OMS案例分析
FF系统Oracle到 OceanBase 数据迁移OMS案例分析
系统基本信息:Oracle源端总共有15张表分区表,22亿条记录需要迁移到Oceanbase 目标端。未做专门优化前,全量迁移耗时11个小时,平均每秒5.5w条记录,速度太慢,不符合客户目标。
第一次优化
优化手段
1、oms 参数调整,增大并发线程,
limitator.platform.threads.number 32 --> 64
limitator.select.batch.max 1200 --> 2400
limitator.image.insert.batch.max 200 --> 400
limitator.datasource.image.ob10freecpu.min=0
2、增大链接数
limitator.datasource.connections.max 50 --> 200
3、jvm内存优化
-server -Xms16g -Xmx16g -Xmn8g -Xss256k --> -server -Xms64g -Xmx64g -Xmn48g -Xss256k
11第二次优化
优化手段
1、OBserver开启日志压缩
ALTER SYSTEM SET clog_transport_compress_all = 'true';
ALTER SYSTEM SET clog_transport_compress_func = 'zlib_1.0';
--租户级别日志压缩
alter system set enable_clog_persistence_compress='true';
2、OBserver 加大转储线程
alter system set _mini_merge_concurrency=32;
alter system set minor_merge_concurrency=32;
3、OBserver加大合并线程数
alter system set merge_thread_count=64;
4、OBserver写入限流
alter system set writing_throttling_trigger_percentage =80;
5、降低转储内存阈值,让obsever提前转储
alter system set freeze_trigger_percentage=30;第三次优化
优化手段
1、清理truncate 掉的分区表元数据
delete from __all_sstable_checksum where sstable_id in
(select table_id from __all_virtual_table_history where table_name='table_namexxx' minus
select table_id from __all_virtual_table where table_name='table_namexxx');
2、租户leader打散到三个zone
alter tenant tenant_name set primary zone='RANDOM';第四次优化
分析OBserver上面的慢SQL,检查发现,慢SQL的执行计划为MULTI_PART_INSERT, 分布式执行计划,因为客户使用的分区表,同时有全局索引,会导致执行计划是分布式执行计划,效率比较差。

优化手段
1、分区表改成非分区表
根据历史经验,单表数据不超过10亿行或者单表容量不超过2000GB可以不考虑分区表
2、临时删除二级索引,只保留主键,待全量迁移完毕后再建二级索引优化结果

OMS数据迁移性能问题排查方法总结
全量迁移关注的性能指标,按照并发维度来,一个并发一般读取源端的网络流量在1-2M之间,使用tsar --traffic --live -i1s查看网络情况,如果网络流入在[并发数*1,并发数*2]M之间则说明正常。rps一般一个并发在1000左右,这个rps和具体的表的数据字段多少,单行记录大小都有关系。


OMS数据迁移性能优化方法总结
我们将OMS数据迁移常用的优化方法总结为下列表格供大家参考,往往可以达到事半功倍的效果。
