
检索增强预训练框架MaskSearch:让AI更聪明地“找答案”
作者:通义大模型 更新时间:2025-06-21 22:25:14 共287人关注



✅ 预训练新范式:增强通用搜索能力
MaskSearch 提出了一种全新的预训练任务——检索增强掩码预测(RAMP) ,让 AI 在大量“填空题”中学习如何调用搜索引擎、多步推理、逐步还原缺失信息,从而掌握通用的搜索与推理能力。
✅ 多智能体协同:生成高质量推理轨迹
通过构建由规划器、重写器、观察器 组成的多智能体系统,MaskSearch 能够自动生成结构清晰、逻辑完整的推理路径(Chain-of-Thought),并借助自进化蒸馏方法快速扩展数据集,为训练提供高质量样本。
✅ 强化学习加持:动态混合奖励机制
采用 DAPO 算法 ,结合格式奖励(保证输出结构正确)与回答奖励(确保内容准确),打造高效强化学习流程,进一步提升模型在复杂任务中的表现。
✅ 小模型也能有大作为
实验表明,即使是小模型(如 Qwen2.5-1.5B),在经过 MaskSearch 预训练后,也能在多个开放域问答任务中取得显著提升。例如,在 Bamboogle 数据集中性能提升超过 11.78% ,真正做到了“小模型也能挑战大模型”。

检索增强掩码预测(RAMP)任务
为了更直观地理解 MaskSearch 的工作原理,我们可以来看一下它的整体架构和训练流程(如下图所示):
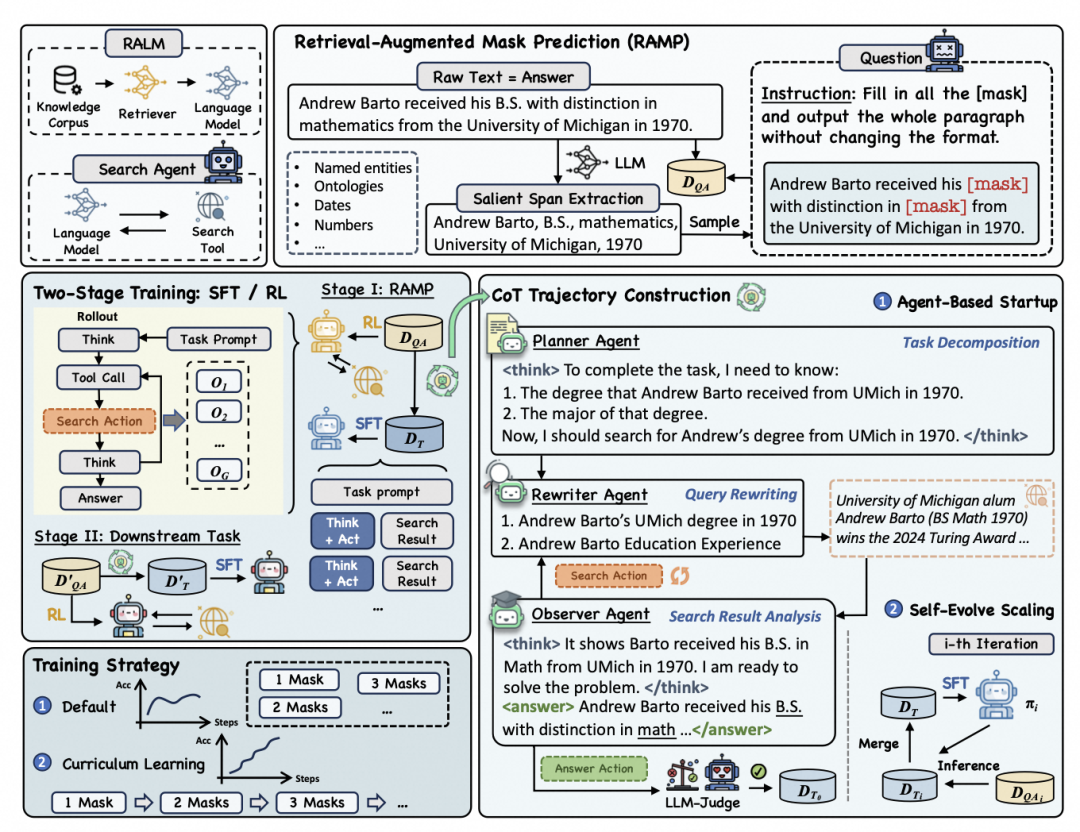
MaskSearch 的核心在于它提出的一种全新预训练任务——检索增强掩码预测(RAMP) ,在这个任务中,模型需要填补句子中的掩码部分,并且必须通过主动搜索和多步推理来完成任务。
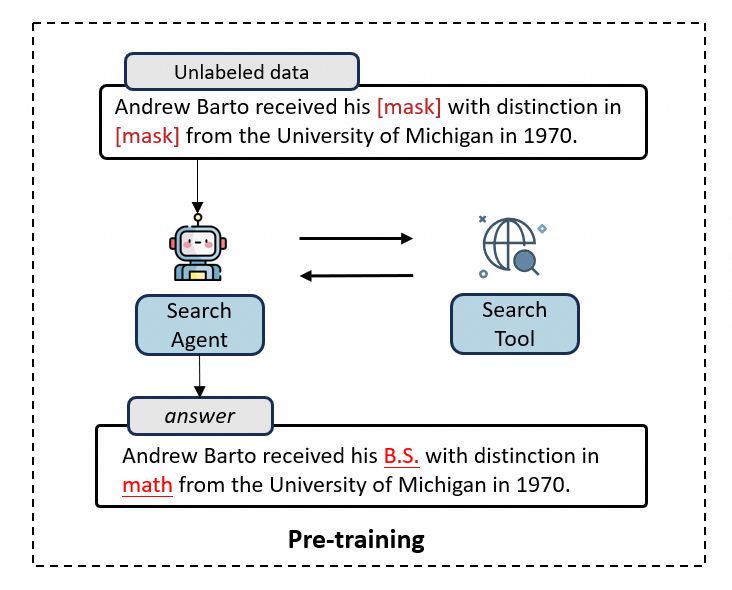
例如,给定一个句子:
Andrew Barto received his [mask] with distinction in [mask] from the University of Michigan in 1970.AI 需要通过搜索引擎查找相关信息,逐步推理出被遮盖的部分。模型首先分析上下文,判断需要查找的信息是“学位类型”和“专业方向”。随后,它调用搜索引擎进行查询,得到关于 Andrew Barto 的相关信息,并从中提取出关键片段:“Andrew Barto, B.S., math, University of Michigan, 1970”。
接着,AI 进行推理整合,最终填补掩码输出完整句子:
Andrew Barto received his B.S. with distinction in math from the University of Michigan in 1970。监督微调(SFT)与强化学习(RL)
为了训练 AI 掌握“找答案”的能力,我们采用了两种训练策略:
(1)监督微调(SFT)
为了生成用于监督微调(Supervised Finetuning, SFT)的思维链(CoT)数据,作者提出 Agent 合成与蒸馏结合的数据生成方法。
-
Agent 合成:首先,搭建多智能体系统,纳入规划、搜索改写、观察分析等角色,协同进行思维链的生成任务。最终由一个 LLM 负责答案判断,仅保留正确答案的思维链。
-
蒸馏:为了快速扩展数据集并保持高质量,使用已有数据训练后的教师模型,直接生成推理轨迹,并逐步迭代教师模型,从而逐步提升数据质量。
(2)强化学习(RL)
在强化学习训练中,采用动态采样策略优化(DAPO) 算法,结合格式奖励与内容奖励,形成一套高效的训练机制。其中,格式奖励检查模型输出是否符合指定格式,回答奖励则使用 Qwen2.5-72B-Instruct 模型评估生成答案与标准答案的一致性。
课程学习策略:从简单到复杂
MaskSearch 还采用了类似“课程学习”的训练方式:根据句子中被掩码的数量划分任务难度,让模型先掌握基础技能,再应对更具挑战性的任务。这种训练方式帮助模型逐步建立扎实的推理能力,并在面对复杂问题时也能从容应对。

为了验证 MaskSearch 的实际效果,研究团队在多个主流问答数据集上进行了系统性实验,涵盖了不同规模的语言模型,并对比了多种训练策略下的表现。
在 HotpotQA、FanoutQA、Musique 等多跳问答任务中,经过 RAMP 预训练的小模型(如 Qwen2.5-1.5B 或 LLaMA-3.2-1B)表现优异,甚至可以媲美更大参数量的模型。这说明,MaskSearch 有效提升了小模型的推理能力,使其具备更强的泛化性和适应性。
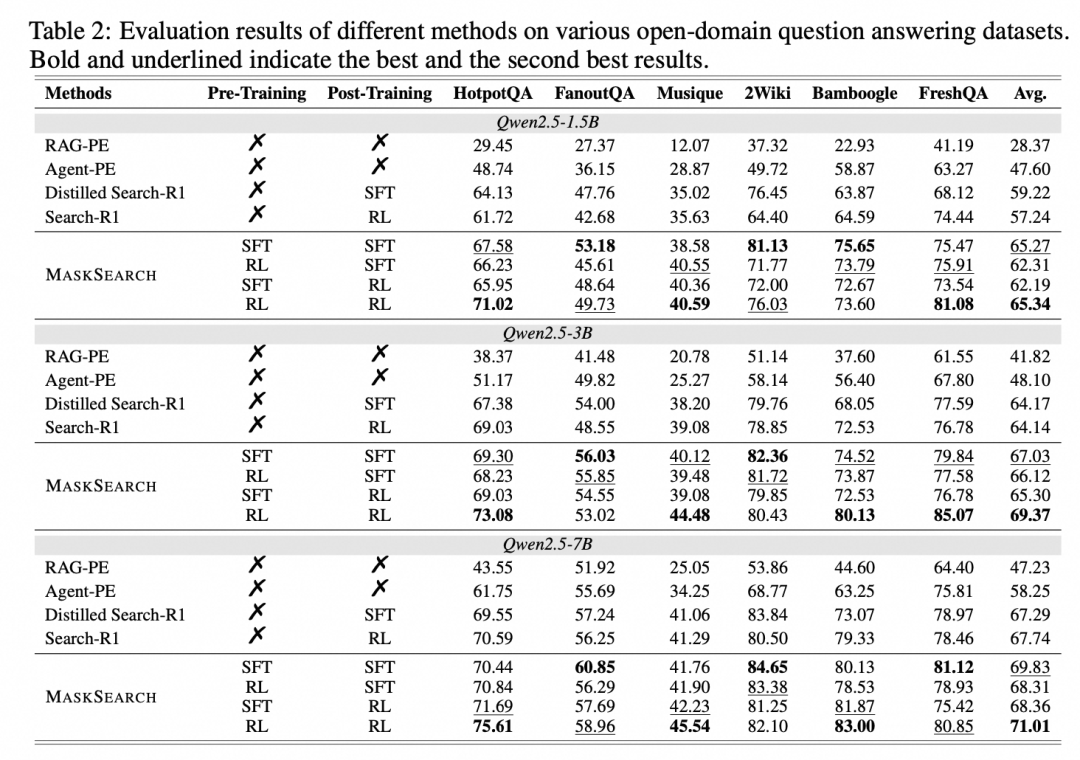
强化学习(RL)在复杂任务中展现出更高的性能上限,尤其在结合 DAPO 算法和混合奖励机制后,模型在召回率、生成质量等方面均优于仅使用监督微调(SFT)的方法。这表明,通过动态采样和奖励引导,AI 能够更精准地优化搜索与推理流程,从而实现更高质量的回答输出。
在验证 MaskSearch 的扩展能力(Scaling Performance)时,我们发现即使是轻量级模型,在经历多轮训练后也能持续提升性能;而大模型虽然增益较小,但依然受益于 RAMP 预训练,显示出该框架良好的通用性和可扩展性。
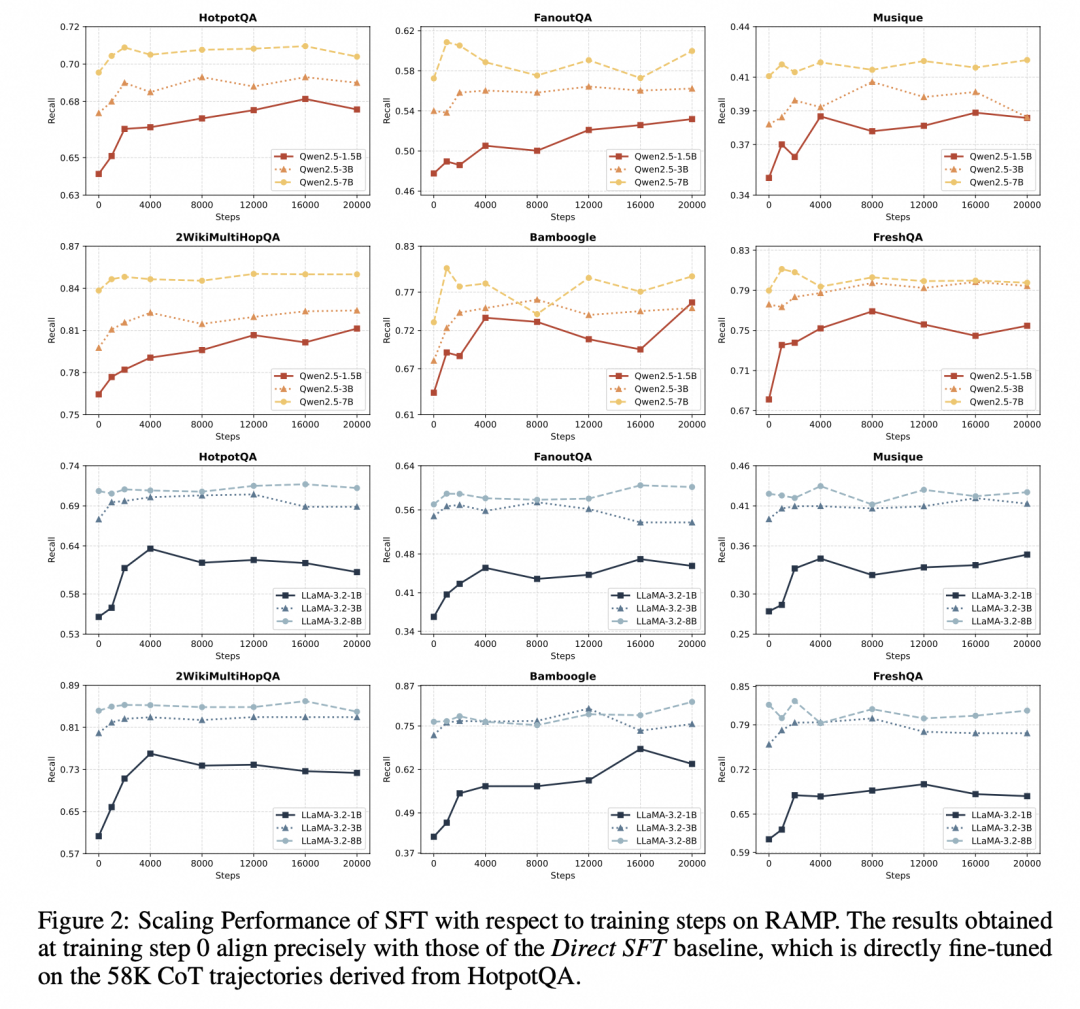
我们还设计了一种基于掩码数量的课程学习策略 ,让模型从简单任务逐步过渡到复杂任务。这种由浅入深的训练方式,显著提升了模型在下游任务中的表现,也验证了难度梯度设计对推理能力构建的重要性。
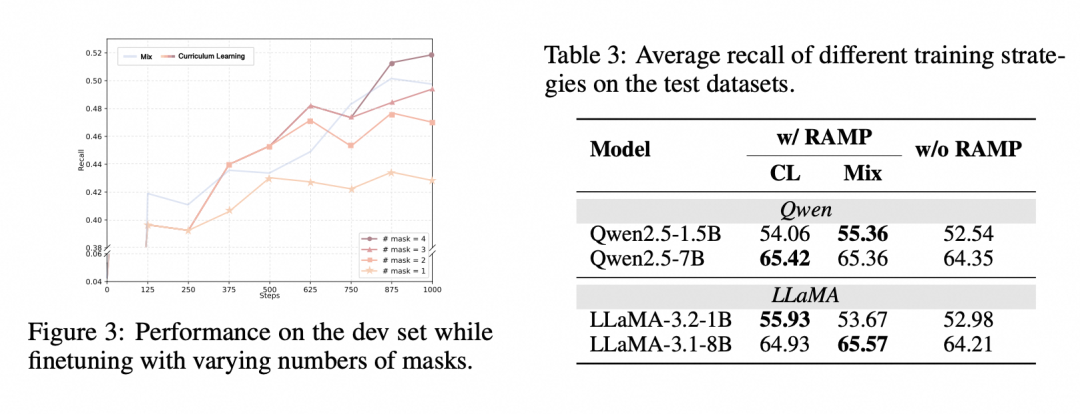
MaskSearch 在多个模型和任务中都展现出良好的适应性和稳定的性能提升,如果你想深入了解 MaskSearch 的训练机制与技术细节,欢迎查看完整论文。
📚论文地址: https://arxiv.org/abs/2505.20285
💻代码库: https://github.com/Alibaba-NLP/MaskSearch
💬 你怎么看?
你希望AI在哪些场景具备“主动搜索 + 推理能力”?

活动截止时间:2025年6月12日17:00
 Qwen 家族再上新!
Qwen 家族再上新! WebDancer:从零训练一个 DeepResearch 类智能体
WebDancer:从零训练一个 DeepResearch 类智能体